How to Measure Citation Attribution Confidence
Learn a page-level way to measure citation attribution confidence so you can stop guessing which content changes worked.
InflectPublished
Quick Summary: Citation attribution confidence is the strength of evidence behind a claim like "this page change caused this result." A useful model separates access, citation, and visit signals before calling something a win.
Most teams can report that they appeared in AI responses. Fewer teams can explain what changed and why it changed. That difference sounds subtle, but it is the gap between anecdotal reporting and operational learning.
This gap matters more now because click behavior is shifting across AI-assisted search journeys. Ahrefs' AI Overviews update points to major CTR compression on informational queries, and Pew's browsing-data analysis shows that users increasingly encounter AI summaries in routine search behavior.
When clicks become less stable, weak attribution models break quickly. Teams that mix unlike signals in one dashboard can no longer tell whether they are seeing progress or noise.
What attribution confidence means in practice
Attribution confidence is the quality of the connection between your action and your outcome. In practice, that means you can tie three things together cleanly: the exact URL that changed, the revision window for that change, and the resulting movement in citation visibility and AI-origin visits.
If any of those links is missing, confidence should drop. Good teams treat this as a feature, not a weakness, because uncertainty made explicit is better than confidence fabricated.
Why most teams mismeasure
The most common failure is collapsing fundamentally different signals into one "AI performance" narrative. Teams combine crawl accessibility, citation appearance, visit movement, and conversion behavior, then interpret the blend as if it were one consistent metric.
That approach is convenient, but it is not actionable. A URL can be crawlable and still uncited. It can be cited and still unclicked. It can get visits for reasons unrelated to your last content revision.
The three-layer confidence model
A reliable model separates access, citation, and visit layers, then evaluates each revision window in order.
Layer 1: Access confidence
First, verify technical eligibility. Check for stable 200 responses, canonical consistency, and no crawler blocking conflicts. Also confirm the content is actually extractable in rendered output.
This is boring work, but it is foundational work. Google's AI features guidance reinforces that AI-facing outcomes still depend on basic search quality and accessibility.
Layer 2: Citation confidence
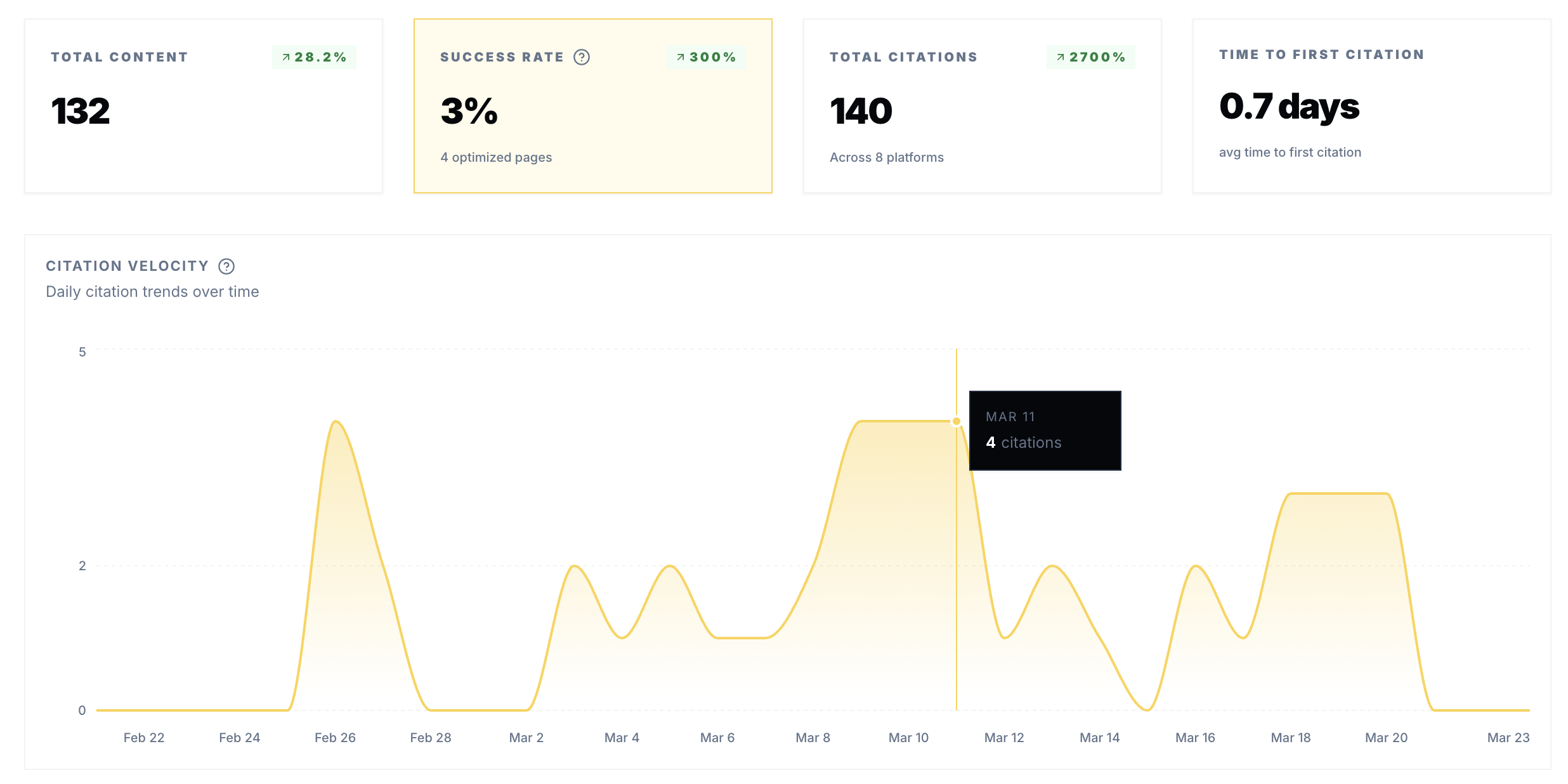
Then track whether that exact URL appears in answer surfaces over time. This is usually the first meaningful signal that a page is being reused in generative responses.
Record citation evidence with enough context to compare like with like: date, surface type, and query or prompt cluster.
Layer 3: Visit confidence
Finally, evaluate whether AI-origin visits move in a direction that is consistent with citation changes. This layer is commercially important, but it is also noisier and easier to misread.
SparkToro's zero-click analysis is a useful reminder that reduced click-through does not automatically invalidate citation gains. Citation progress and traffic progress can move on different timelines.
A practical scoring rubric
Use a simple 0-to-4 rubric with one point per verified criterion:
- Access point: Page eligibility is confirmed within the revision window.
- Citation point: There is measurable citation movement for the specific URL.
- Visit point: AI origin visit movement aligns with the overall citation direction.
- Isolation point: No major confounding releases or campaigns occurred in the same window.
Scores of 0 or 1 indicate noise or insufficient evidence to draw conclusions. A score of 2 provides directional learning but is not yet repeatable. Scores of 3 or 4 identify strong candidates for pattern reuse across your broader content portfolio. Scores of 0 or 1 usually mean the window is too noisy or under-instrumented. A score of 2 often gives directional signal but not repeatable confidence yet. Scores of 3 or 4 are usually strong enough to reuse the pattern across similar pages.
What to log per revision
For each meaningful update, log the URL, the revision identifier (optimizationId or equivalent), and publish time. Then log access checks, citation events, AI-origin visit observations, and the final confidence score with a short rationale.
This is what makes wins reproducible. Without revision-level records, teams can only tell stories about outcomes, not explain them.
Decision rules that improve outcomes
Adopting a few strict rules dramatically reduces false positives:
For the operating model behind this workflow, align your measurement loop with the Pricing constraints and the company framing in About.
- Do not claim a win based solely on traffic movement without citation evidence.
- Do not start attribution windows until all technical access checks pass.
- Do not stack major unrelated edits in a single testing window.
- Do not report aggregate scorecards without underlying URL level evidence.
Frequently Asked Questions
What does attribution confidence replace? It replaces anecdotal mention tracking with rigorous page level decision evidence.
Can Google Search Console alone do this? No. It provides valuable context but lacks the necessary revision level lineage.
What if referrer data is partial? Use controlled redirects where possible and combine them with landing path and timing evidence.
Should we score every content edit? Score only the specific revisions you intend to learn from or repeat at scale.
Ready to measure which page changes improved AI citations? Start with a free domain crawl →